Exactly one year ago, I published here the results of the measuring and enhancing of
EMF Compare 1.3 scalability in which I detailed how we greatly improved the comparison times, and how we had observed that EMF Compare was a glutton in terms of memory usage. At the time, we did isolate a number of improvement axes... And they were part of what made us go forward to a new major version, EMF Compare 2.0.
Now that
2.0 is out of the oven, and that we are rid of the 1.* stream limitations, it was time to move on to the next step and make sure we could
scale to millions! We continued the work started last year as part of the
modeling platform working group on the support for
logical resources in EMF Compare.
The main problem was that EMF Compare needed to load two (or three, for comparisons with VCSs) times the whole logical model to compare. For large models, that quickly reached up to huge amount of required heap space. The idea was to be able to determine beforehand which of the fragments really needed to be loaded : if a model is composed of 1000 fragments, and only 3 out of this thousand have changed, it is a huge waste of time and memory to load the 997 others.
To this end, we tried with EMF Compare 1.3 to make use of Eclipse Team's "logical model" APIs. This was promising (as shown in last year's post about our performances then), but limited since the good behavior of this API depends on the VCS providers to properly use them. In EMF Compare 2, we decided on circumventing this limitation by using our own implementation of a logical model support (see the
wiki for more on that).
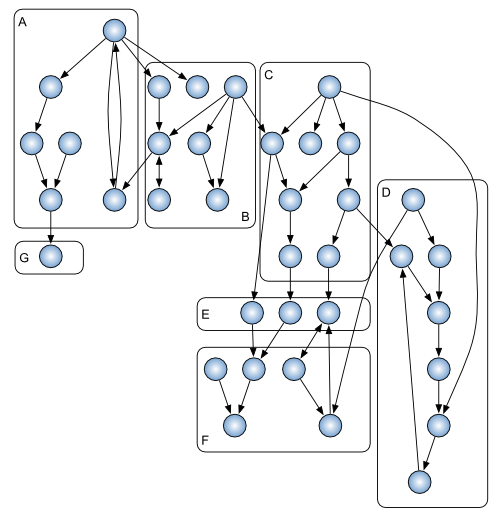
As a quick explanation, an EMF model can be seen as a set of elements referencing each other. This is what we call a "logical model" :
However, these elements are not always living in memory. When they are serialized on disk, they may be saved into a single physical file, or they can be split across
multiple files, as long as the references between these files can be
resolved :
If we remain at the file level, this logical model can be seen as a set of 7 files :
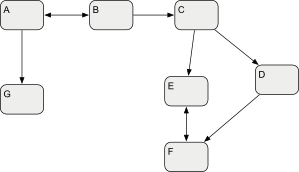
Now let's suppose that we are trying to compare a modified copy (
left) of this model with a remote version (
right). This requires a three-way comparison of left, right and their common ancestor,
origin. That would mean loading all 21 files in memory in order to recompose the logical model. However, suppose that only some of these files really did change (blue-colored hereafter) :
 |  |
| Left | Right |
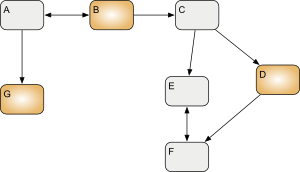
In such a case, what we need to load is actually a small part of the 21 total files. For each three sides of the comparison, we only need to load the ones that can potentially show differences :
Which means that we only need to load 9 out of the 21 files, for 58% less memory than what EMF Compare 1 needed (if we consider all files to be of equal "weight"). Just imagine if the whole logical model was composed of a thousand fragments instead of 7, allowing us to load only 9 files out of the total 3000!
With these enhancements, we decided to run the very same tests as what we did last year with EMF Compare 1.3. Please take a look at my
old post for the three sample models' structure and the test modus operandi. I will only paste here as a reminder :
The models' structure :
|
|
|
|
|
|
|
Small |
Nominal |
Large |
|
Fragments |
99 |
399 |
947 |
|
Size on disk (MB) |
1.37 |
8.56 |
49.9 |
|
|
|
|
|
|
Packages |
97 |
389 |
880 |
|
Classes |
140 |
578 |
2,169 |
|
Primitive Types |
581 |
5,370 |
17,152 |
|
Data Types |
599 |
5,781 |
18,637 |
|
State Machines |
55 |
209 |
1,311 |
|
States |
202 |
765 |
10,156 |
|
Dependencies |
235 |
2,522 |
8,681 |
|
Transitions |
798 |
3,106 |
49,805 |
|
Operations |
1,183 |
5,903 |
46,029 |
|
Total element count |
3,890 |
24,623 |
154,820 |
And the
Time and memory used required to compare each of the model sizes with EMF Compare 1.3 :
|
|
|
|
|
|
|
Small |
Nominal |
Large |
|
Time (seconds) |
6 |
22 |
125 |
|
maximum Heap (MB) |
555 |
1,019 |
2,100 |
And without further ado, here is how these figures look like with EMF Compare 2.1 :
|
|
|
|
|
|
|
Small |
Nominal |
Large |
|
Time (seconds) |
5 |
13 |
48 |
|
maximum Heap (MB) |
262 |
318 |
422 |
In short, EMF Compare now scales much more smoothly than it did with the 1.* stream, and it requires
a lot less memory than it previously did. Furthermore, the one remaining time sink are the I/O and model parsing activities. The comparison in itself being reduced to only a few seconds.
For those interested, you can find a much more detailed description of this work and the decomposition of the comparison process on
the wiki.