So what can you really expect from Compare 2.1? Let's skip the project life and focus on the cool features that can now be used.
Graphical Comparison
We introduced a "preview" support of the graphical display of differences into the project in its fifth milestone (M5) back in february. This was one of the biggest features we wanted to polish for the release, and polished it has been :).
This support is quite generic, and it should be able to handle most GMF-based modelers without too much work from their side (a few extensions are needed to tell EMF Compare how to open their diagrams). For now, our primary target was Papyrus.
Though the differences themselves were all pretty well detected, we were not happy with how they were displayed in this first draft. The decorators we use to tell the users "what changed in there?" were thus our primary focus. Here are a few examples of the differences that can be detected in Papyrus UML diagrams... and how we display them in said diagrams.
- Adding a Class
Both "new" and "old" models are displayed, on the left and right sides respectively. The Class "A" has been added : it is highlighted in the left (new) diagram, and a transparent placeholder for its shape is shown over the right (old) diagram.
- Removing a feature
Within lists, the placeholder is shown as a single line:
- And if we need some context to understand the change?
Some changes cannot be understood if shown alone. For example, cascading differences (delete a package and all of its content) need some context to understand the differences related to said "content". Likewise, if we delete both sides of an association along with the association itself, we'll need contextual information to understand the association difference. This is handled through lighter-colored placeholders.

- What about conflicts?
In case of conflicts, we try and highlight all related information on all three sides of the comparison:





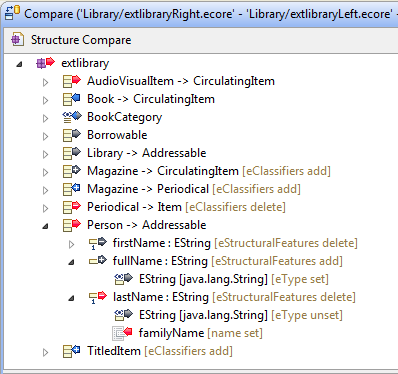
One of the hardest part of comparing EMF models is that we need to "match" the elements contained by these models together. When we are given two instances of a given model in two different versions, we need a way to tell that some package "library" in the first version is the same element as the package "library" in the second version. Likewise, we need to be able to tell that the attribute "pages" of a class "Book" in the first is the same as the attribute "length" of the class "Book" in the second version before we can even tell that there is a difference on that attribute (it has been renamed).
When we have identifiers in our model, this is an easy matter. We assume that the identifier of one given object has not changed between the two versions. However, this is not always (rarely, in fact) the case. EMF Compare 2.1.0 re-introduces support for such models, computing and matching objects through their similarity. For example, here is the result of comparing two ecore files together:

The amout of data we compute is quite large, reflecting the accuracy we desire for the comparison; and the number of differences between two versions of the same model can be daunting. We strived to improve the comparison UI in order to provide a much more precise and intelligible information. We've used two means to that end, both of which can be extended by clients of the API.
- Grouping differences together
By default, EMF Compare does not group differences, and simply displays them as they've been detected:One of the options we provide by default lets you group these differences according to their originating side (in the case of three-way comparisons, comparing with a remotely controlled version for example), along with a special group for the conflicts (if any):

- Filtering differences out of the view
A second option (of course, both can be combined) to limit the number of visible information is to filter out differences that could be considered somewhat as "noise". For example, EMF Compare detects all differences within the containment tree: if the Class "Book" has been removed, then of course its attribute "pages" has been removed. And in turn, the "type" of this attribute has been unset. Those are three differences resulting from a single one. By default, EMF Compare will not display the "resulting" differences, focusing on the "root" only:However, they are still computed, and they are still there in the comparison. We called these "cascading" differences, and users can choose to have them displayed instead by unticking the associated filter:

This has already become too long of a post (kudos if you read all the way till here ;)). Anyone interested in the full list of enhancements and highlights of this release can find it here on the project's wiki, with a little more details.